Thesis: Assessing Homogeneity of the Data Generating Process for Supervised Learning
Traditional ML pipelines assume the entire training set comes from one data-generating process, but today's data are often too diverse for that to hold. We recast the usual combined algorithm-and-hyperparameter search (CASH) as partitioned CASH (PCASH): first cluster the data into more homogeneous groups, then optimize models within each cluster. Experiments on synthetic data and the Boston Housing set show that this automatic partitioning makes models far more robust to hidden heterogeneity. In fact, PCASH cuts root-mean-squared error by 26 % versus the standard approach when using multiple linear regression. This suggests embracing multiple sub-processes, not one, can materially improve generalization.
Tired of Misattribution, Fatigue in the NBA
In the 2021 CMU Sports Analytics REU, my team researched how player fatigue influences NBA game outcomes. We scraped and engineered 300+ variables from a decade of tracking data, showing media narratives around fatigue are often overstated. Our framework isolates factors that truly swing results.
Stanford AI Index Experiments
I ran a suite of HPC experiments that feed into Stanford’s 2021 AI Index report, tracking global progress in AI. My runs populated performance benchmarks cited in the final publication.
Let's Stock About the Environment
First-place project at the 2021 TAMU Datathon (Goldman Sachs challenge). We modeled relationships between environmental metrics and market behavior, adjusting for growth in the US economy.
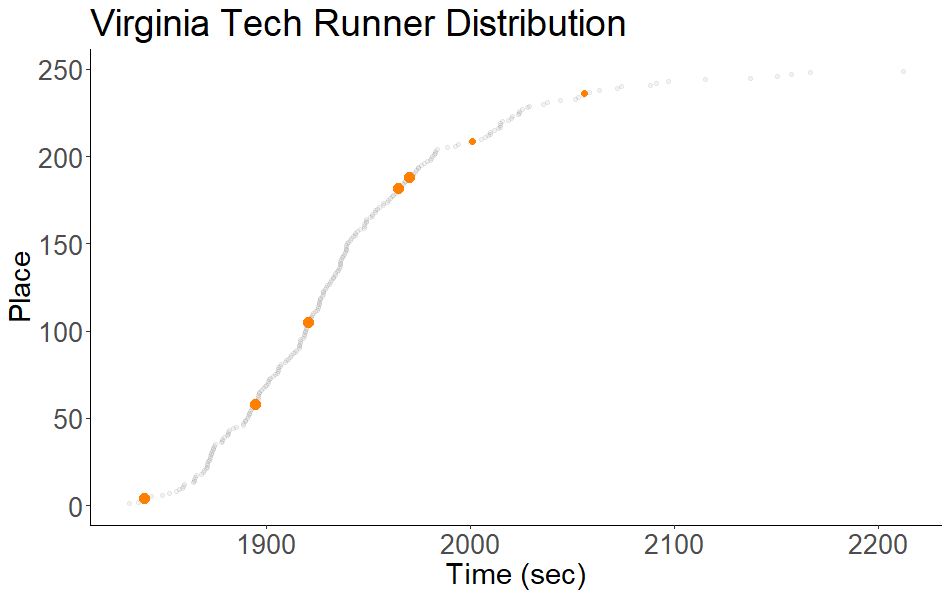
Cross-Country Optimization
A script that ranks runners by the marginal impact of their performance on team scores, exploiting the near-Gaussian distribution of finishing places in XC races.